The Mozilla JavaScript-engine team has been hard at work since the shiny new JägerMonkey Just-In-Time compiler hit the betas. We're viciously ripping apart any bug that stands between us and shipping Firefox 4. One could say that we're coming at you like a SpiderMonkey.
Alongside our ferocious fixing, one of our late-game performance initiatives was to get all of our polymorphic inline caches (AKA PICs) enabled on ARM devices. It was low risk and of high benefit to our Firefox for Mobile browser, whose badass-yet-cute codename is Fennec.
Jacob Bramley and I took on this ARM support task in bug 588021, obviously building on excellent prior inline cache work from fellow team members David Anderson, Dave Mandelin, Sean Stangl, and Bill McCloskey.
tl;dr: Firefox for Mobile fast on ARM. Pretty graphs.
Melts in your mouth, not in your ARM
To recap, JägerMonkey is also known as the "method compiler": it takes a method's bytecode as input and orders up the corresponding blob of machine code with some helpful information on the side. Its primary sub-components are the register tracker, which helps the compiler transform the stack-based bytecode and reuse already-allocated machine registers intelligently, and the MacroAssembler, which is the machine-code-emitting component we imported from Webkit's Nitro engine.
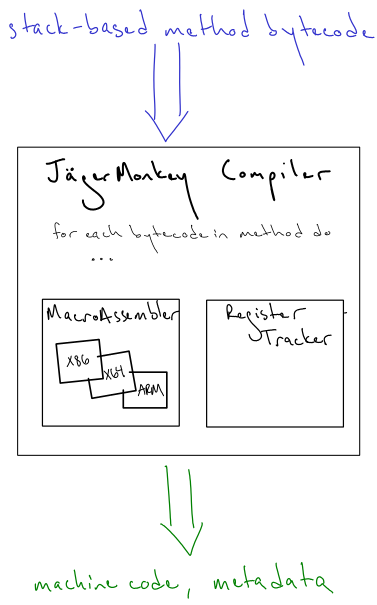
The MacroAssembler is the secret sauce for JägerMonkey's platform independence. It's an elegantly-designed component that can be used to emit machine code for multiple target architectures: all of x86, x86-64, and ARM assembly are supported through the same C++ interface! This abstraction is the reason that we only need one implementation of the compiler for all three architectures, which has been a clear win in terms of cross-platform feature additions and maintainability.
"So", you ask, "if you've got this great MacroAssembler-thingy-thing, why didn't all the inline caches work on all the platforms to begin with?" Or, alternatively, "If all the compiler code is shared among all the platforms, why didn't all the inline caches crash on ARM?"
The answer is that some platform-specifics had crept into our compiler code!
ARM'd and ifdef-dangerous
As explained in the entry on inline caches, an inline cache is a chunk of self-modifying machine code. A machine code "template" is emitted that is later tweaked to reflect the cached result of a common value. If you're frequently accessing the nostrilCount property of Nose objects, inline caches make that fast by embedding a shortcut for that access into the machine code itself.
In the machine code "template" that we use for inline caches, we need to know where certain constants, like object type and object-property location, live as offsets into the machine code so that we can change them later, during a process called repatching. However, when our compiler says, "If this value is not 0xdeadbeef, go do something else," we wind up with different encodings on each platform.

As you may have guessed, machine-code offsets are different for each platform, which made it easier for other subtle platform-specifics to creep into the compiler as well.
To answer the question raised earlier, the MacroAssembler interface wasn't heavily relied on for the early inline cache implementations. Inline caches were first implemented for x86, and although x86 is a variable-width instruction set, all of the instruction sequences emitted from the compiler had a known instruction width and format. [*] This permitted us to use known-constant-offset values for the x86 platform inline caches. These known-constant-offsets never changed and so didn't require any space or access time overhead in side-structures. They seemed like the clear solution when x86 was the only platform to get up-and-running.
| [*] | For example, if you always emit a simple mov from a 32-bit register to a 32-bit register, that has a known constant length. The "variable width" part of "variable width instruction set" refers to the fact that different instructions do not generally take the same number of bytes. It does not mean that the encoding of a given instruction (like mov) with particular operands (like two 32-bit registers) is totally variable. |
Then x86-64 (AKA x64) came along, flaunting its large register set and colorful plumage. On x64, the instruction sequence did not have a known width and format! Depending on whether the extended register set is used, things like mov instructions may require a special REX prefix byte in the instruction stream (highlighted in blue above). This led to more ifdefs -- on x64 a bunch more values have to be saved in order to know where to patch our inline caches!
As a result, getting inline caches working on ARM was largely a JägerMonkey refactoring effort. Early on, we had used conditional compilation (preprocessor flags) to get inline caches running on a platform-by-platform basis, which was clearly the right decision for rapid iteration, but we decided that it was time to pay down some of our technical debt.
Paying down the debt: not quite an ARM and a leg
The MacroAssembler deals with raw machine values -- you can tell it dull-sounding machine-level things like, "Move this 17 bit sign-extended immediate into the EAX register."
On the other hand, we have our own awesome-sounding value representation in the SpiderMonkey engine: on both 32-bit and 64-bit platforms every "JS value" is a 64-bit wide piece of data that contains both the type of the data and the data itself. [†] Because the compiler is manipulating these VM values all the time, when we started the JägerMonkey compiler it was only natural to put the MacroAssembler in a delicious candy coating that also knew how to deal with these VM values.
| [†] | The team also believes that further experimentation with a 128-bit value representation for 64-bit systems could yield positive results. |
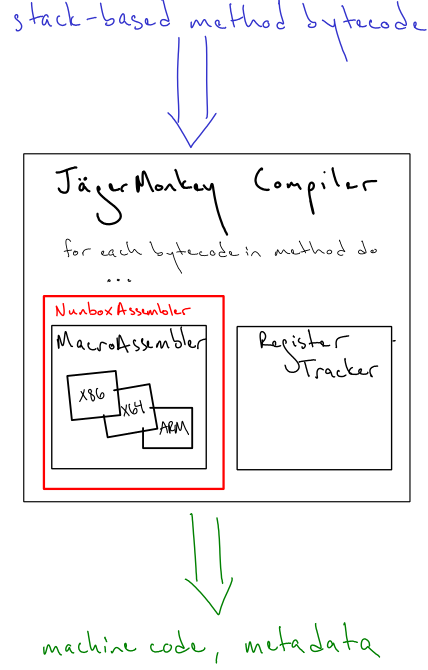
The NunboxAssembler, pictured in red, [‡] is a specialized assembler with routines to deal with our "nunbox" value representation. [§] The idea of the refactoring was to candy-coat a peer of the MacroAssembler, the Repatcher, with routines that knew how to patch common inline cache constructs that the NunboxAssembler was emitting.
With the inline cache Repatcher in place, we were once again able to move all the platform-specific code out of the compiler and into a single, isolated part of the code base, hidden behind a common interface.
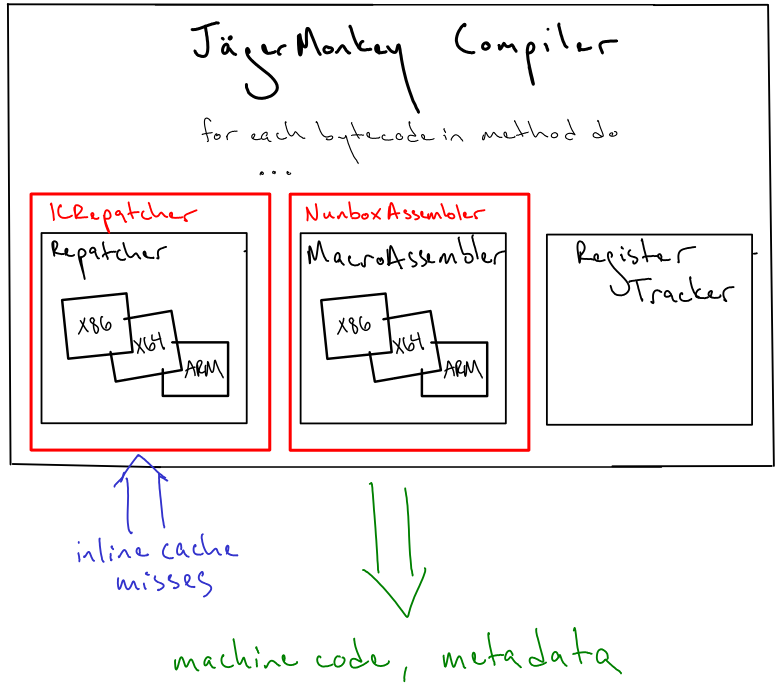
Routines like NunboxAssembler::emitTypeGuard, which knows how to emit a type guard regardless of the platform, are paired with routines like ICRepatcher::patchTypeGuard(newType), which knows how to patch a type guard regardless of platform. Similarly, NunboxAssembler::loadObjectProperty has a ICRepatcher::patchObjectPropertyLoad. The constructs that are generated by the NunboxAssembler are properly patched by the corresponding ICRepatcher method on a miss. It's all quite zen.
| [‡] | FD&C Red No. 40, to be precise. |
| [§] | "Nunbox" is a play on the term NaN-boxing. We have no idea how Luke comes up with these names, but we hope he never stops. |
Frog ARMs
On real devices running the Fennec betas, we've seen marked improvements since Beta 3. [¶] Most notably, we've leapfrogged the stock Android 2.2 browser on the V8-V5 benchmark on both the Galaxy S and the Nexus One. Pretty graphs courtesy of Mark Finkle.
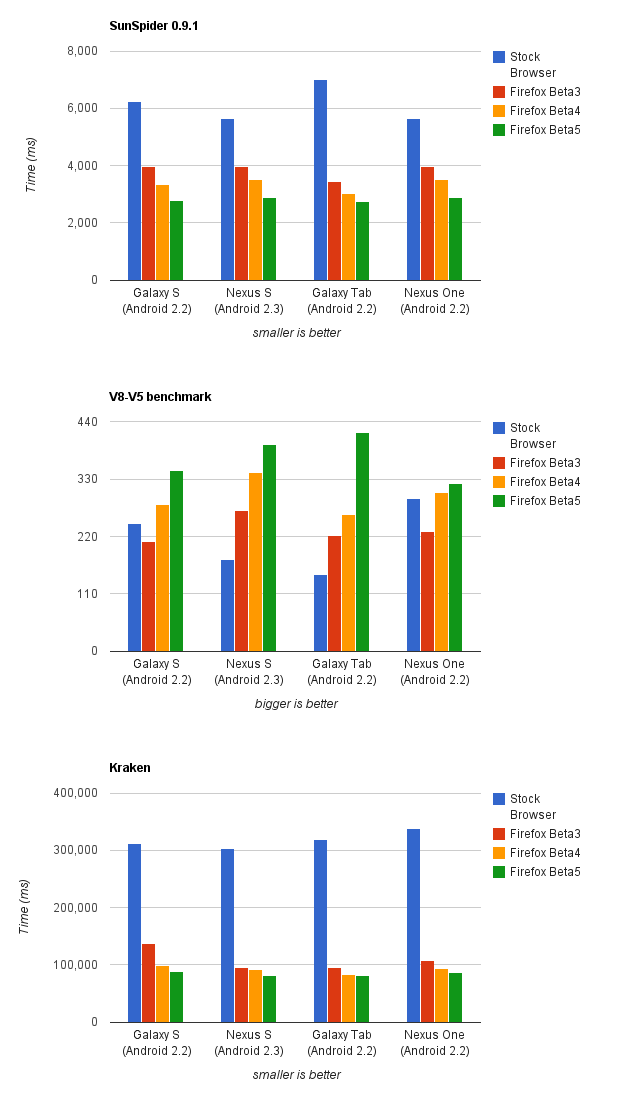
| [¶] | On the fancy Tegra 2 board I was developing on, running the SunSpider harness on the JavaScript shell with methodjit-only, this work net us a whopping 230% speedup on the V8-V4 benchmark and a 15% speedup on SunSpider 0.9.1. |
ARMn't you glad I didn't say banana?
Since I've run out of remotely-acceptable ARM malapropisms, these topics will be left to further discussion. Feel free to comment on anything that deserves further clarification!
- Why does the JägerMonkey ARM back-end emit fixed-width ARMv7 machine code, instead of Thumb2?
- How are JägerMonkey exceptions implemented on ARM? (It's slightly different from x86/x64.)
- What are the current development platform limitations?
- How does the compiler prevent a constant pool from being dumped into the code stream?