Inline caching is a critical ingredient in the delicious pie that is dynamic language performance optimization. What follows is a gentle-albeit-quirky introduction to what polymorphic inline caches (PICs) are and why they're useful to JavaScript Just-In-Time compilers like JaegerMonkey.
But first, the ceremonial giving of the props: the initial barrage of PIC research and implementation in JaegerMonkey was performed by Dave Mandelin and our current inline cache implementations are largely the work of David Anderson. As always, the performance improvements of Firefox's JavaScript engine can be monitored via the Are We Fast Yet? website.
C is for speed, and that's good enough for me
C is fast.
Boring people (like me) argue about astoundingly interesting boring things like, "Can hand-tuned assembly be generally faster than an equivalent C program on modern processor architectures?" and "Do languages really have speeds?", but you needn't worry -- just accept that C is fast, and we've always been at war with Eurasia.
So, as we've established, when you write a program in C, it executes quickly. If you rewrite that program in your favorite dynamic language and want to know if it still executes quickly, then you naturally compare it to the original C program.
C is awesome in that it has very few language features. For any given snippet of C code, there's a fairly direct translation to the corresponding assembly instructions. [*] You can almost think of C as portable assembly code. Notably, there are (almost) zero language features that require support during the program's execution -- compiling a C program is generally a non-additive translation to machine code.
| [*] | This is as opposed to, say, C++, where in any given snippet of code the == operator could be overloaded. |
Dynamic languages like JavaScript have a massive number of features by comparison. The language, as specified, performs all kinds of safety checks, offers you fancy-n-flexible data record constructs, and even takes out the garbage. These things are wonderful, but generally require runtime support, which is supplied by the language engine. [†] This runtime support comes at a price, but, as you'll soon see, we've got a coupon for 93 percent off on select items! [‡]
| [†] | "Engine" is a sexy term, but it's just a library of support code that you use when language constructs don't easily fall into the translate-it-directly-to-machine-code model used by C. |
| [‡] | Coupon only applies to idealized property access latencies. Competitor coupons gladly accepted. Additional terms and restrictions may apply. See store for details. |
You now understand the basic, heart-wrenching plight of the performance-oriented dynamic language compiler engineer: implement all the fancy features of the language, but do it at no observable cost.
Interpreters, virtual machines, and bears
"Virtual machine" sounds way cooler than "interpreter". Other than that, you'll find that the distinction is fairly meaningless in relevant literature.
An interpreter takes your program and executes it. Generally, the term "virtual machine" (AKA "VM") refers to a sub-category of interpreter where the source program is first turned into fake "instructions" called bytecodes. [§]
| [§] | Alternative interpreter designs tend to walk over something that looks more like the source text -- either an abstract syntax tree or the program tokens themselves. These designs are less common in modern dynamic languages. |

I call these instructions fake because they do things that a hardware processing units are unlikely to ever do: for example, an ADD bytecode in JavaScript will try to add two arbitrary objects together. [¶] The point that languages implementors make by calling it a "virtual machine" is that there is conceptually a device, whether in hardware or software, that could execute this set of instructions to run the program.
| [¶] | There have historically been implementations that do things like this; notably, the Lisp machines and Jazelle DBX. The JavaScript semantics for ADD are particularly hairy compared to these hosted languages, because getting the value-for-adding out of an object can potentially invoke arbitrary functions, causing re-entrance into JavaScript interpretation. |
These bytecodes are then executed in sequence. A program instruction counter is kept in the VM as it executes, analogous to a program counter register in microprocessor hardware, and control flow bytecodes (branches) change the typical sequence by indicating the next bytecode instruction to be executed.
Virtual (machine) reality
Languages implemented in "pure" VMs are slower than C. Fundamentally, your VM is a program that executes instructions, whereas compiled C code runs on the bare metal. Executing the VM code is overhead!
To narrow the speed gap between dynamic languages and C, VM implementers are forced to eliminate this overhead. They do so by extending the VM to emit real machine instructions -- bytecodes are effectively lowered into machine-codes in a process called Just-In-Time (JIT) compilation. Performance-oriented VMs, like Firefox's SpiderMonkey engine, have the ability to JIT compile their programs.
The term "Just-In-Time" is annoyingly vague -- just in time for what, exactly? Dinner? The heat death of the universe? The time it takes me to get to the point already?
In today's JavaScript engines, the lowering from bytecodes to machine instructions occurs as the program executes. With the new JaegerMonkey JIT compiler, the lowering occurs for a single function that the engine sees you are about to execute. This has less overhead than compiling the program as a whole when the web browser receives it. The JaegerMonkey JIT compiler is also known as the method JIT, because it JIT compiles a method at a time.
For most readers, this means a few blobs of x86 or x86-64 assembly are generated as you load a web page. The JavaScript engine in your web browser probably spewed a few nice chunks of assembly as you loaded this blog entry.
Aside: TraceMonkey
In SpiderMonkey we have some special sauce: a second JIT, called TraceMonkey, that kicks in under special circumstances: when the engine detects that you're running loopy code (for example, a for loop with a lot of iterations), it records a stream of bytecodes that corresponds to a trip around the loop. This stream is called a trace and it's interesting because a) it can record bytecodes across function calls and b) the trace optimizer works harder than the method JIT to make the resulting machine code fast.
There's lots more to be said about TraceMonkey, but the inline caching optimization that we're about to discuss is only implemented in JaegerMonkey nowadays, so I'll cut that discussion short.
The need for inline caching
In C, accessing a member of a structure is a single "load" machine instruction:
struct Nose {
int howManyNostrils;
bool isPointy;
};
bool isNosePointy(struct Nose *nose) {
return nose->isPointy;
}
The way that the members of struct Nose are laid out in memory is known to the C compiler because it can see the struct definition -- getting the attribute nose->isPointy translates directly into a load from the address addressof(nose) + offsetof(Nose, isPointy).
Note: Just to normalize all the terminology, let's call the data contained within a structure the properties (instead of members) and the way that you name them the identifiers. For example, isPointy is an identifier and the boolean data contained within nose->isPointy is the property. The act of looking up a property through an identifier is a property access.
On the other hand, objects in JavaScript are flexible -- you can add and delete arbitrary properties from objects at runtime. There is also no language-level support for specifying the types that an identifier can take on. As a result, there's no simple way to know what memory address to load from in an arbitrary JavaScript property access.
Consider the following snippet:
function isNosePointy(nose) {
return nose.isPointy;
}
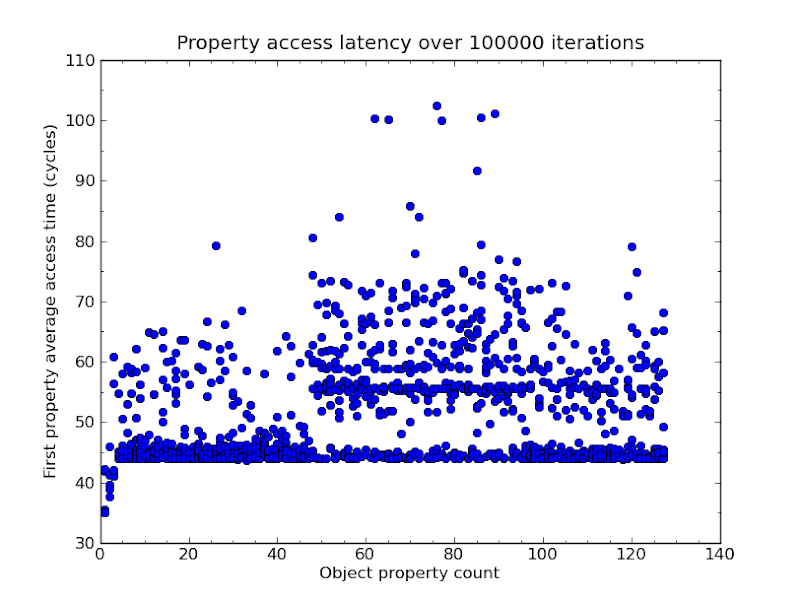
To get at the isPointy property, the JavaScript VM emits a single bytecode, called GETPROP, which says "pull out the property with the identifier isPointy". [#] Conceptually, this operation performs a hash-map lookup (using the identifier as a key), which takes around 45 cycles in my microbenchmark. [♠]
| [#] | In the bytecode stream the value isPointy is encoded as an immediate. |
| [♠] | Note that there is actually further overhead in turning the looked-up property into an appropriate JavaScript value. For example, there are additional checks to see whether the looked-up value represents a "getter" function that should be invoked. |
The process of "looking up a property at runtime because you don't know the exact type of the object" falls into a general category of runtime support called dynamic dispatch. Unsurprisingly, there is execution time overhead associated with dynamic dispatch, because the lookup must be performed at runtime.
To avoid performing a hash-map lookup on every property access, dynamic language interpreters sometimes employ a small cache for (all) property accesses. You index into this cache with the runtime-type of the object and desired identifier. [♥] Resolving a property access against this cache under ideal circumstances takes about 8.5 cycles.
| [♥] | This is, in itself, a small hash-map lookup, but the hash function is quite fast. At the moment it's four dependent ALU operations: right shift, xor, add, and. |

WTF is inline caching already!?
So we've established that, with good locality, JS property accesses are at least 8.5x slower than C struct property accesses. We've bridged the gap quite a bit from 45x slower. But how do we bridge the gap even bridgier?

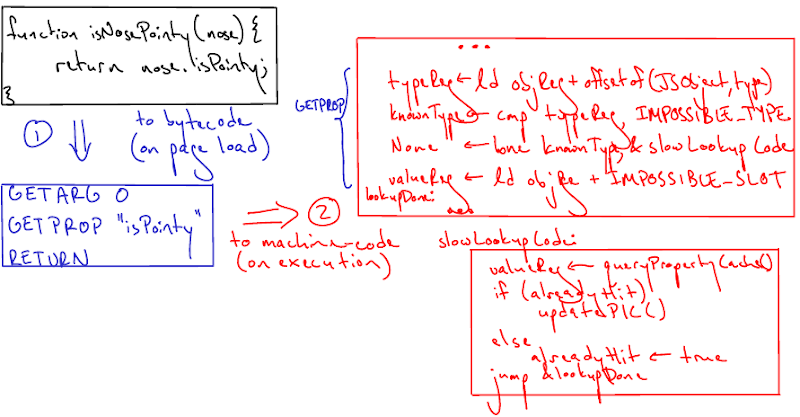
The answer is, surprisingly, self-modifying code: code that modifies code-that-currently-exists-in-memory. When we JIT compile a property access bytecode, we emit machine-code that looks like this:
type <- load addressof(object) + offsetof(JSObject, type)
shapeIsKnown <- type equals IMPOSSIBLE_TYPE
None <- goto slowLookupCode if shapeIsKnown is False
property <- load addressof(object) + IMPOSSIBLE_SLOT
Now, if you ask Joe Programmer what he thinks of that code snippet, he would correctly deduce, "The slow lookup code will always be executed!" However, we've got the self-modifying code trick up our sleeves. Imagine that the type matched, so we didn't have to go to the slow lookup code -- what's our new property access time?
One type load, one comparison, an untaken branch, and a property value load. Assuming good locality/predictability and that the object's type happened to already be in the register (because you tend to use it a lot), that's 0+1+1+1 == 3 cycles! Much better.
But how do we get the types to match? Joe Programmer is still looking pretty smug over there.
The trick is to have the slowLookupCode actually modify this snippet of machine code! After slowLookupCode resolves the property in the traditional ways mentioned in previous sections, it fills in a reasonable value for IMPOSSIBLE_TYPE and IMPOSSIBLE_SLOT like they were blank fields in a form. This way, the next time you run this machine code, there's a reasonable chance you won't need to go to slowLookupCode -- the types might compare equal, in which case you can perform a simple load instruction to get the property that you're looking for!
This technique of modifying the JIT-compiled code to reflect a probable value is called inline caching: inline, as in "in the emitted code"; caching, as in "cache a probable value in there". This the basic idea behind inline caches, AKA ICs.
Also, because we emit this snippet for every property-retrieving bytecode we don't rely on global property access patterns like the global property cache does. We mechanical mariners are less at the mercy of the gods of locality.
Where does "P" come from?
Er, right, we're still missing a letter. The "P" in "PIC" stands for polymorphic, which is a fancy sounding word that means "more than one type".
The inline cache demonstrated above can only remember information for a single type -- any other type will result is a shapeIsKnown of False and you'll end up going to the slowLookupCode.
Surveys have shown that the degree of polymorphism (number of different types that actually pass through a snippet during program execution) in real-world code tends to be low, in JavaScript [♦] as well as related languages. However, polymorphism happens, and when it does, we like to be fast at it, too.
| [♦] | Gregor Richards published a paper in PLDI 2010 that analyzed a set of popular web-based JS applications. The results demonstrated that more than eighty percent of all call sites were monomorphic (had the same function body). I'm speculating that this correlates well to the property accesses we're discussing, though that wasn't explicitly established by the research -- in JS, property access PIC are easier to discuss than function invocation PICs. In related languages, like Self, there is no distinction between method invocation and property access. |
So, if our inline cache only supports a single type, what can we do to handle polymorphism? The answer may still be surprising: self-modify the machine code some more!
Before we talk about handling the polymorphic case, let's recap the PIC lifecycle.
The PIC lifecycle
The evolution of the PIC is managed through slowLookupCode, which keeps track of the state of the inline cache in addition to performing a traditional lookup. Once the slow lookup is performed and the PIC evolves, the slowLookupCode jumps back (to the instruction after the slot load) to do the next thing in the method.
When a PIC is born, it has that useless-looking structure you saw in the previous section -- it's like a form waiting to be filled out. The industry terminology for this state is pre-monomorphic, meaning that it hasn't even seen one (mono) type pass through it yet.
The first time that inline cache is executed and we reach slowLookupCode we, shockingly, just ignore it. We do this because there is actually a hidden overhead associated with modifying machine code in-place -- we want to make sure that you don't incur any of that overhead unless there's an indication you might be running that code a bunch of times. [♣]
| [♣] | "Hidden overhead my foot! Where does it come from?" Today's processors get a little scared when you write to the parts of memory that contain code. Modern processor architecture assumes that the memory you're executing code out of will not be written to frequently, so they don't optimize for it. [**]
|
The second time we reach the slowLookupCode, the inline cache is modified and the PIC reaches the state called monomorphic. Let's say we saw a type named ElephantTrunk -- the PIC can now recognize ElephantTrunk objects and perform the fast slot lookup.
When the PIC is monomorphic and another type, named GiraffeSnout, flows through, we have a problem. There are no more places to put cache entries -- we've filled out the whole form. This is where we get tricky: we create a new piece of code memory that contains the new filled-out form, and we modify the original form's jump to go to the new piece of code memory instead of slowLookupCode.
Recognize the pattern? We're making a chain of cache entries: if it's not an ElephantTrunk, jump to the GiraffeSnout test. If the GiraffeSnout fails, then jump to the slowLookupCode. An inline cache that can hit on more than one type is said to be in the polymorphic state.

There's one last stage that PICs can reach, which is the coolest sounding of all: megamorphic. Once we detect that there are a lot of types flowing through a property access site, slowLookupCode stops creating cache entries. The assumption is that you might be passing an insane number of types through this code, in which case additional caching would only only slow things down. For a prime example of megamorphism, the 280slides code has an invocation site with 1,437 effective types! [††]
| [††] | I'm citing Gregor Richards yet again. |
Conclusion
There's a lot more to discuss, but this introduction is rambling enough as-is -- if people express interest we can further discuss topics like:
- Why in the name of Knuth is it okay to perform a linear search of the types in the inline cache? Can't we do better?
- What are all the types of inline caches that you currently implement? What bytecodes do they correspond to? Who are the handsome fellows who implemented each of those inline caches and are they currently seeing anybody?
- Why are you talking about types in a language like JavaScript, where typeof o is almost always "object"?!
- What happens if the property lives on a prototype of the object, instead of the object itself? ...then it can't be a simple slot load! I feel hurt and betrayed... what other caveats haven't been discussed!?
- Why might you choose to use monomorphic inline caches (MICs) instead of using PICs everywhere?
- Does the TraceMonkey execution time suffer because hits in the inline cache prevent fills of the (global) property cache?
- What kick-arse optimizations related to PICs have been discussed in the literature that have yet to be implemented in JaegerMonkey?
- What the crap have I been talking about this whole time?
Suffice it to say that JavaScript gets a nice speed boost by enabling PICs: x86 JaegerMonkey with PICs enabled is 25% faster on SunSpider than with them disabled on my machine. [‡‡] If something makes a dynamic language fast, then it is awesome. Therefore, inline caches are awesome. (Modus ponens says so.)
| [‡‡] | MICs give a nice percentage boost as well, but they're harder to disable at the moment, or I'd have numbers for that too. |